The blog.
News, guides, and insights about self-hosted GitHub Actions runners.
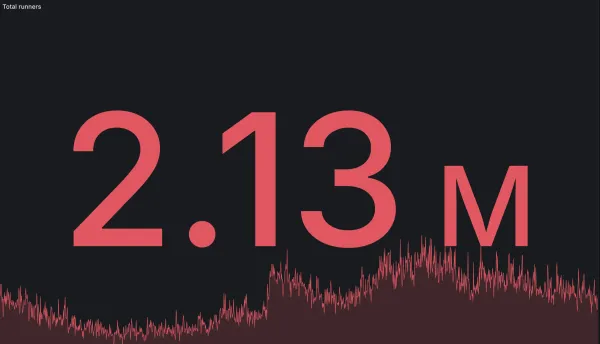
RunsOn handled 2.13 million GitHub Actions jobs in a single day
RunsOn crossed two million daily GitHub Actions jobs for the first time, setting a new record at 2.13 million jobs in one day.
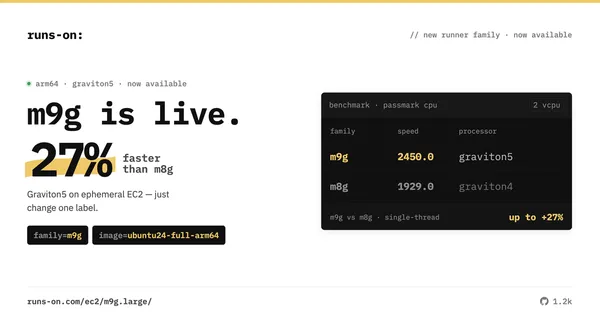
M9g ARM64 runners: ~30% faster single-thread than Graviton4 or GitHub's runners
RunsOn can now launch GitHub Actions ARM64 runners on Graviton5-based M9g instances: ~27% faster single-thread than m8g, ~31% faster than GitHub's ARM64.
Tier-based pricing for Flex and Fleet
One license now covers both RunsOn products, priced on monthly runner volume across four tiers. Existing subscriptions stay on their current plan.
Introducing RunsOn Fleet
A new scale-set mode for GitHub Actions runners on AWS. Built for platform teams that want a reviewed, fixed catalog instead of per-job labels.
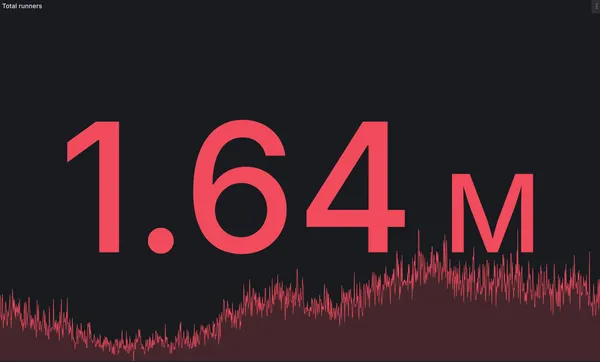
RunsOn handled 1.64 million GitHub Actions jobs in a single day
RunsOn reached a new milestone with 1.64 million GitHub Actions jobs handled in a single day.
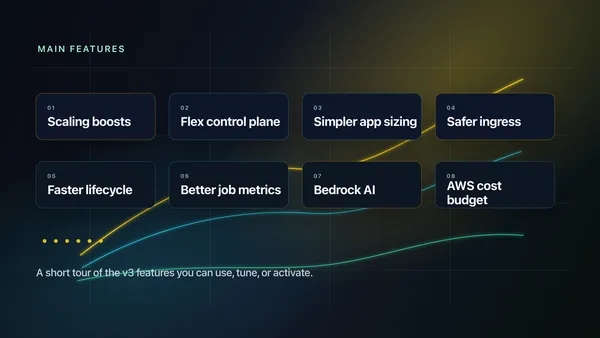
What's new in RunsOn v3
A short tour of RunsOn v3: scaling boosts, the new Flex control plane, simpler sizing, safer ingress, faster cleanup, better metrics, and AWS cost budgets.

The road to v3
RunsOn v3 started as an App Runner migration, but became a larger cleanup of the control plane, CloudFormation stack, and deployment model.

RunsOn is finally on Terraform/OpenTofu
RunsOn now supports Terraform and OpenTofu starting with v2.11.0, alongside the existing CloudFormation deployment path.

How building a Terraform module made me fall in love with CloudFormation
Building the RunsOn Terraform module made me rethink CloudFormation and where it is still the right deployment tool.
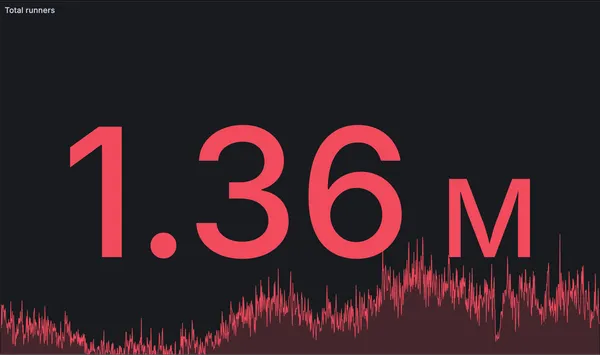
New record: 1.36 million GitHub Actions jobs in a single day
RunsOn hits a new record with 1.36 million GitHub Actions jobs processed in a single day, up from 990k just six weeks ago.

BuildJet Is Shutting Down. Here’s What I’d Replace It With
BuildJet is discontinuing service. Don’t just swap one hosted runner vendor for another — decide what you want from CI, then pick the model that matches.

From freelancer to running ~1.5% of all GitHub Actions jobs: Building RunsOn as a solo founder
How frustrations with CI/CD bottlenecks turned into RunsOn and scaled to 1.18M jobs per day.
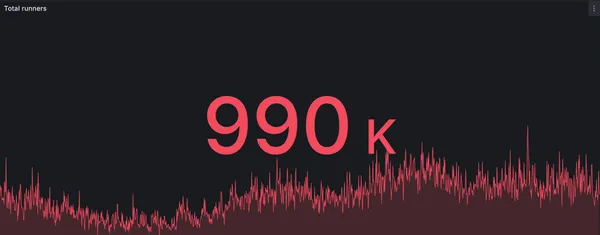
New record: RunsOn processes 990k jobs in a single day
RunsOn hits a new milestone with nearly 1 million GitHub Actions jobs processed in a single day

GitHub to charge $0.002/min for self-hosted runners starting March 2026
GitHub announced billing changes for self-hosted runners. Our pricing calculator and tables now show exactly how the new fee affects your CI costs.

Cloud-init tips and tricks for EC2 instances
Useful cloud-init commands to troubleshoot and inspect EC2 instances.
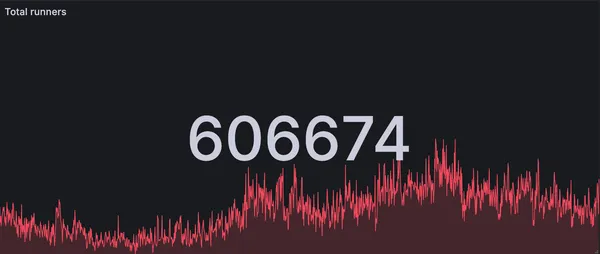
RunsOn is now handling more than 600k jobs per day
How we handle 600k+ jobs per day with RunsOn, the best solution for running GitHub Actions in your own infrastructure

Your CI runners are shared mutable state
Long-lived self-hosted runners accumulate state, secrets, and drift across every job. The case for treating each job as a clean slate instead.
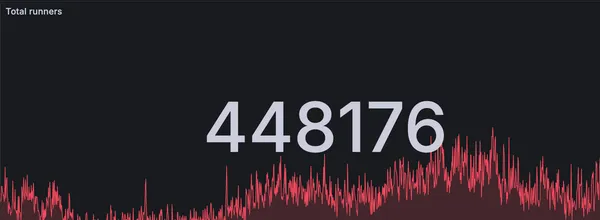
RunsOn is now handling more than 400k jobs per day
How we handle 400k+ jobs per day with RunsOn, the best solution for running GitHub Actions in your own infrastructure

The true cost of self-hosted GitHub Actions - Separating fact from fiction
Analysis of self-hosted GitHub Actions runners' costs and challenges, and how RunsOn solves these problems with minimal overhead and maximum savings.

🚀 v2.8.2 is out, with EFS, Ephemeral Registry support, and YOLO mode (tmpfs)!
Speed up docker builds with the ephemeral registry, share files across workflow jobs with EFS, and speed up your builds with tmpfs!
StepSecurity Partnership
RunsOn partners with StepSecurity to defend CI/CD runners against supply chain attacks: network monitoring, file integrity checks, and security insights.
v2.6.5 - Optimized GPU images, VpcEndpoint stack parameter, tags for custom runners
v2.6.4 and v2.6.5 have been released in the last weeks, with the following changes.
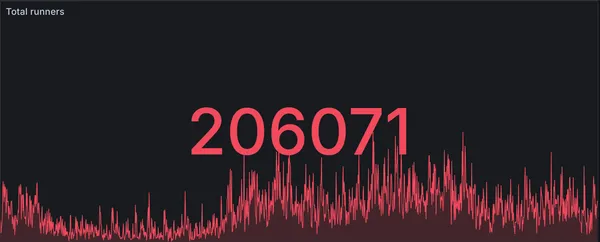
RunsOn is now handling 200k jobs per day
How we handle 200k jobs per day with RunsOn, the best solution for running GitHub Actions in your own infrastructure

Faire des économies avec ses propres runners
More about RunsOn (in French) in this podcast.

GitHub Actions are slow and expensive, what are the alternatives?
GitHub's default runners are 2 slow cores at a premium price. The real alternatives — artisanal, productized, and SaaS self-hosted runners — compared.

How to verify that VPC traffic to S3 is going through your S3 gateway?
Not properly checking your route tables could lead to high bills and slower throughput.

GitHub Actions runner images (AMI) for AWS EC2
Fast, optimized AWS AMIs for GitHub Actions runners. Updated every 2 weeks.

Use GitHub App manifests to symplify your GitHub App registration flow
GitHub App manifests let you register an App from a plain HTML form and a few lines of JavaScript, instead of walking users through the settings UI.

How to setup docker with NVIDIA GPU support on Ubuntu 22
Install the CUDA drivers and nvidia-container-toolkit on Ubuntu 22, configure the Docker runtime, and confirm the container sees the GPU with nvidia-smi.

Automatically cleanup outdated AMIs in all AWS regions
A script that deletes Amazon Machine Images older than a given threshold across every AWS region, while always keeping the two most recent AMIs per region.

How to setup GitHub hosted runner with a simple cloud-init script
A single Bash script that provisions a GitHub Actions runner non-interactively — Docker, extra packages, a dedicated user — and doubles as cloud-init.