From freelancer to running ~1.5% of all GitHub Actions jobs: Building RunsOn as a solo founder
For years building CI/CD pipelines for clients, the same bottleneck kept showing up: runners that were slow, expensive, and unreliable.
And it was not just one client or platform. From Jenkins to Travis CI, the issues were identical. Even after GitHub Actions launched in 2019 and everyone switched because they were already on GitHub, the underlying problems stayed.
The machines were mediocre and cost way more than they should have.
Around that time, I was working with the CEO of OpenProject ↗, whose developers had been complaining about CI for weeks. They were spending more time fixing obscure CI issues than building product. And when it did work, it was slow - test suites that took 20 to 30 minutes overall to run, and that was with heavy test sharding across multiple runners.
So we put together a task force to build CI that was fast, cheap, and most importantly, predictable.
Looking back, that is what started everything.
The first version
Section titled “The first version”We started by evaluating what was already out there:
- Third-party SaaS solutions were out because you are still handing your code and secrets to a third party. That is a non-starter for many teams.
- Actions Runner Controller looked promising, but I did not have the time or desire to become a Kubernetes expert just to keep CI running.
- Other tools like AWS CodeBuild and Bitbucket were expensive and not meaningfully faster or more reliable.
“Would I genuinely want this in my own workflow?” was the question guiding every decision, and none of those options passed.
So we self-hosted Actions on a few bare-metal Hetzner servers. Simple, fast, and under our control.
Or so we thought.
The setup worked great at first. But then we hit the classic problem with persistent hosts: maintenance. I was constantly writing cleanup scripts or chasing weird concurrency issues.
It was not ideal.
Then GitHub released ephemeral self-hosted runners. You could spin up a fresh VM for each job and auto-terminate it after. No concurrency overlap, no junk piling up over time.
But at the time it was still new. Webhook handling was flaky, and Hetzner instances could not be trusted to boot quickly. That is when I realized a more established platform like AWS made sense. I rewrote everything from scratch on the side, just to see how much better it could be (OpenProject later switched to it). The philosophy was:
- Make it ephemeral: EC2s that auto-terminate, eliminating runner drift and cleanup toil.
- Make it frictionless: use boring, managed AWS services wherever possible.
- Make it cheap: App Runner for the control plane.
No warm pools (we have them now), no clever tricks. Just solid fundamentals.
That became the first real version of RunsOn.
The scale shock
Section titled “The scale shock”A few months later, one early user hit 10,000 jobs in a single day.
It was Alan ↗, who were also the first to show trust and sponsor the project.
I remember staring at the metrics thinking, “there is no way this is right.” Almost all of those jobs came from a single org. I did not realize one company could run that many jobs in 24 hours.
That is when it clicked: if one org could do 10k jobs, what would this look like at scale?
I panicked a little. My architecture was not going to cut it for much longer.
For the longest time I worried about provider limits. My experience with Hetzner and Scaleway taught me that spinning up 10+ VMs at once was asking for trouble: quotas, failed boots, stalled builds.
Alan hitting 10k jobs was actually a blessing. After some back-and-forth with AWS to raise EC2 quotas, we could finally spawn as many instances as we needed. That gave me the confidence to tell bigger prospects “yes, this will scale” without sweating it.
The cost surprise
Section titled “The cost surprise”The AWS move also changed how I thought about the problem.
Initially I was laser-focused on compute performance: faster instances, quicker boot times. I was naive to think EC2 would be the main expense.
Then I looked at the bills for my own installation.
Network egress was eating me alive. A lot of workflows were hitting GitHub’s cache hard, which meant data transfer costs were way higher than expected.
So I said, “I am already on AWS. Why not use S3 for caching? Why not optimize AMIs to cut EBS?”
I built those features to save money. But they made everything faster too. S3 cache was quicker than GitHub’s native cache, and leaner images meant faster boots.
I was trying to fix a cost problem and accidentally unlocked better performance.
From 10k to 1.18M jobs in a day
Section titled “From 10k to 1.18M jobs in a day”Here is a snapshot from our internal dashboard showing 1.18M total runners in a single day. Since each job spins up its own runner, that is over 1M jobs in 24 hours.
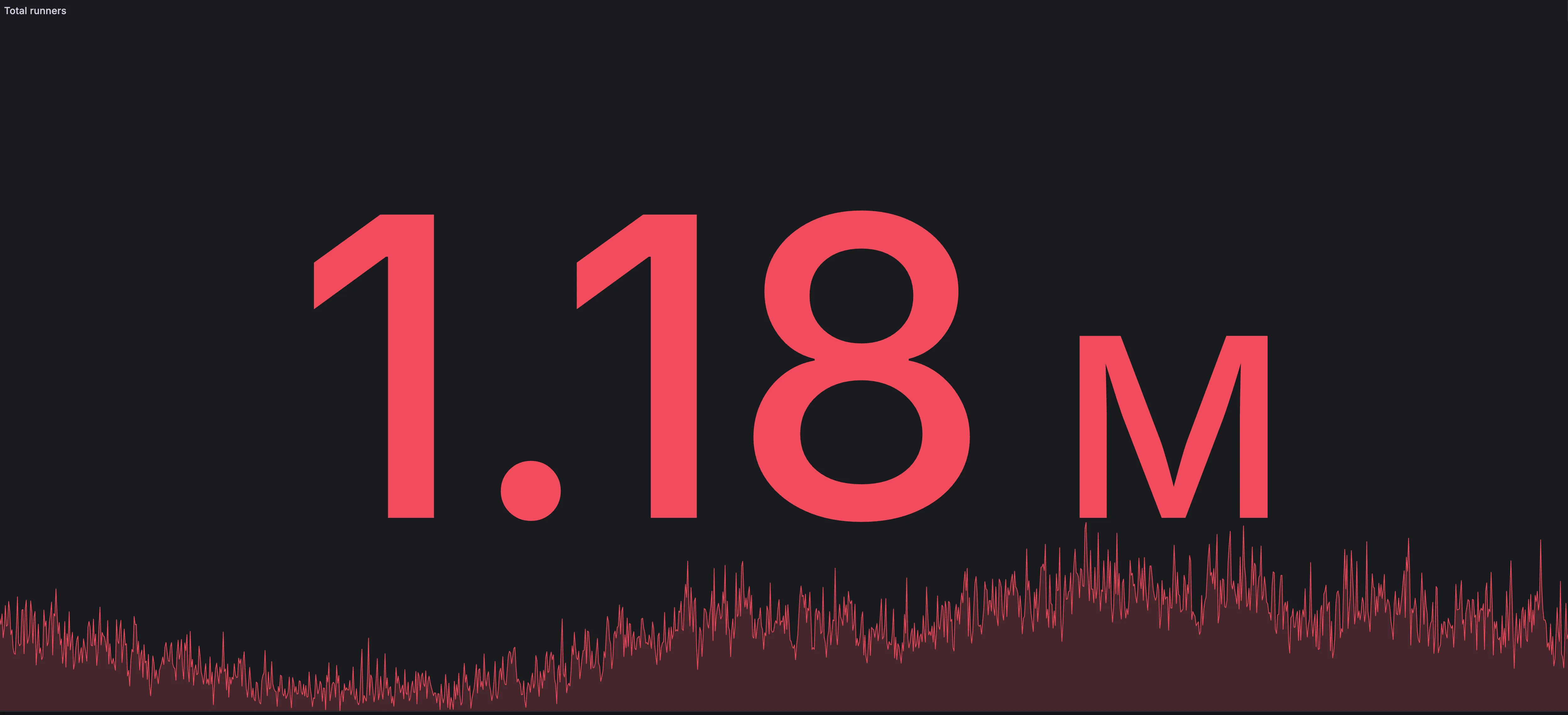
Based on publicly released GitHub Actions numbers, that puts RunsOn at roughly ~1.5% of GitHub Actions volume.
So yes, I will always be grateful to Tim and the team at Alan for trusting me to experiment and rewrite RunsOn to make it scale. That architecture unlocked 100k jobs, then 400k, then 800k, and now over 1 million jobs in a day.
What building for developers taught me
Section titled “What building for developers taught me”I thought nailing the architecture would be the main thing.
Turns out developers want fast answers when something breaks. I have seen what happens when CI is blocked and support takes three days to respond. So I aim for hours, not days.
Handling support as a solo founder is stressful - especially when requests come in while I am asleep - but it is also rewarding to harden the product so those issues happen less and less.
Another principle that has stayed true: RunsOn should work without requiring people to change their workflow files (because I would not want to).
I also made the source code available for audit. Developers are rightfully skeptical of black boxes running their code. I get it. If I were evaluating a tool that had to handle thousands of jobs a day for an enterprise, I would want to see the code too.
Building devtools is always a challenge, because developers often have a high bar for such tools. But they are also the ones who will tell you exactly what is broken and what would make it better (looking at you, Nate).
That feedback loop is what made RunsOn what it is today.
The best scale tests come from customers who push you the hardest.
Where this goes next
Section titled “Where this goes next”The biggest request I hear is cost visibility. People want to understand exactly what is costing them money and where to optimize. So I am building cost transparency features that show per-job and per-repo breakdowns.
Same thing with efficiency monitoring. If your jobs are taking longer than they should, you want to know why. That request is coming directly from users.
Every time someone pushes RunsOn into a new scale or use case, I learn something new about what breaks and what should exist. The customers who push the hardest are the ones who make it better for everyone else.
We are at about 1.18M jobs a day now. Let us see where the next million takes us.
If your CI is frustrating you, give RunsOn a try. I would love to hear what you think.