OpenTelemetry
Exact OTEL signal behavior for RunsOn
This page is the authoritative OpenTelemetry reference for RunsOn. It explains exactly what RunsOn emits, when it emits it, and where the automatic behavior stops.
Server-side behavior
When OtelExporterEndpoint is configured, the RunsOn server exports OTLP metrics and traces from the server process. That includes the RunsOn-defined server metrics inventory below plus the Go runtime appendix.
Prometheus remains a separate legacy /metrics compatibility surface. It is useful when you already have scrape-based monitoring, but it is not the same transport as OTLP and it does not cover runner-side signals.
Runner-side behavior
Current RunsOn runners already use the local collector for the built-in job-metrics flow. Add extras=otel to a job label, or to the runner spec used by a pool, when you also want runner-side OTLP export.
- The collector always writes local
metrics.jsonlfor the built-in job-metrics flow. - Remote OTLP export only happens when the runner has OTEL enabled and the stack OTLP endpoint is configured.
- RunsOn exports the same default runner host-metrics set on Linux and Windows.
Logs
RunsOn forwards the runner bootstrap log file (output.log) through the local collector when runner OTEL is enabled.
This is the RunsOn bootstrap and agent log path. It is not the full GitHub workflow job log stream.
If the EC2 instance log group is configured, the same bootstrap log file also remains available through the instance log group path in CloudWatch.
Traces
RunsOn emits server traces plus agent and instance lifecycle traces.
Per-step job spans are also automatically emitted to your OTLP backend after a job completes. Those spans are emitted from the RunsOn server and you don’t need to set extras=otel on your jobs to get them.
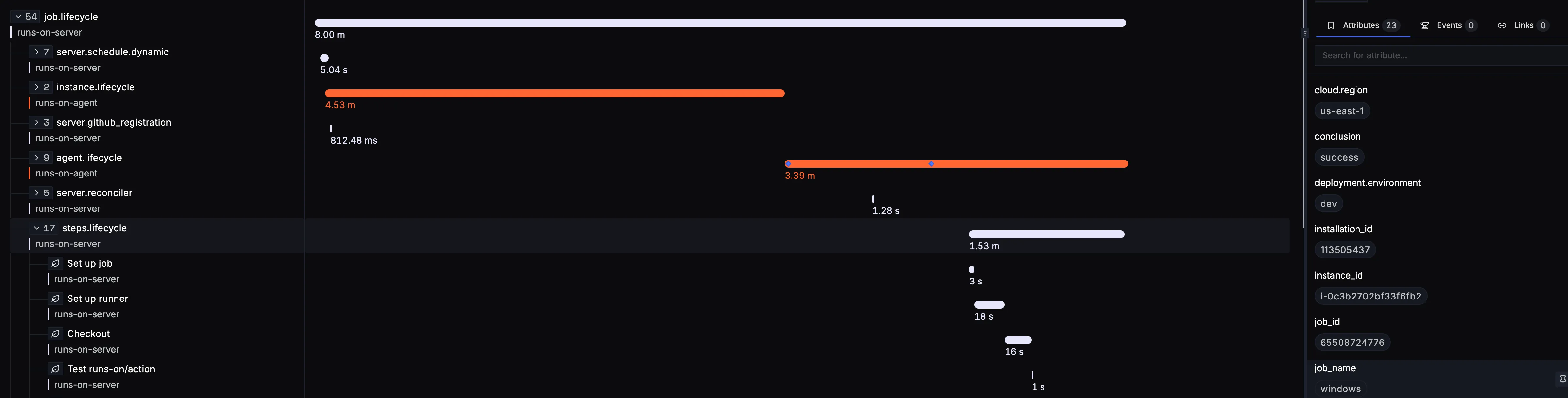
Inline job metrics vs OTLP export
The inline job-summary flow described on Job metrics is separate from remote OTLP export. A job can have local summary charts without sending runner metrics to your observability backend.
Generated metric inventory
RunsOn server metrics
| Metric | Kind | Unit | Description | Attributes | Transport |
|---|---|---|---|---|---|
runs_on_jobs_total | counter | {job} | Total number of jobs by status. | conclusioninstance_familyinstance_lifecycleinstance_typeinterruptedorgpool_namepool_typerepo_full_namestatusworkflow_name | Exported through OTLP metrics when the stack OTLP endpoint is configured. Exposed on the server Prometheus /metrics surface when the endpoint is enabled. |
runs_on_internal_queue_duration_seconds | histogram | s | Time from job queued in RunsOn to scheduled. | conclusioninstance_familyinstance_lifecycleinterruptedpool_namestatus | Exported through OTLP metrics when the stack OTLP endpoint is configured. Exposed on the server Prometheus /metrics surface when the endpoint is enabled. |
runs_on_overall_queue_duration_seconds | histogram | s | Time from job queued by GitHub to started. | conclusioninstance_familyinstance_lifecycleinterruptedpool_namestatus | Exported through OTLP metrics when the stack OTLP endpoint is configured. Exposed on the server Prometheus /metrics surface when the endpoint is enabled. |
runs_on_job_duration_seconds | histogram | s | Time from job started to completed. | conclusioninstance_familyinstance_lifecycleinterruptedpool_namestatus | Exported through OTLP metrics when the stack OTLP endpoint is configured. Exposed on the server Prometheus /metrics surface when the endpoint is enabled. |
runs_on_pool_instances_total | observable_gauge | {instance} | Current number of pool instances by state. | installation_idorgpool_namestate | Exported through OTLP metrics when the stack OTLP endpoint is configured. Exposed on the server Prometheus /metrics surface when the endpoint is enabled. |
runs_on_rate_limiter_tokens | observable_gauge | {token} | Available tokens in a rate limiter. | limiter | Exported through OTLP metrics when the stack OTLP endpoint is configured. Exposed on the server Prometheus /metrics surface when the endpoint is enabled. |
runs_on_rate_limiter_burst | observable_gauge | {token} | Burst capacity of a rate limiter. | limiter | Exported through OTLP metrics when the stack OTLP endpoint is configured. Exposed on the server Prometheus /metrics surface when the endpoint is enabled. |
runs_on_spot_circuit_breaker_active | observable_gauge | 1 | Whether the spot circuit breaker is active; 1 means active and 0 means inactive. | - | Exported through OTLP metrics when the stack OTLP endpoint is configured. Exposed on the server Prometheus /metrics surface when the endpoint is enabled. |
runs_on_github_operations_total | counter | {operation} | Total number of GitHub API operations by operation name. | github_operation | Exported through OTLP metrics when the stack OTLP endpoint is configured. Exposed on the server Prometheus /metrics surface when the endpoint is enabled. |
runs_on_aws_operations_total | counter | {operation} | Total number of AWS API operations by operation name. | aws_operation | Exported through OTLP metrics when the stack OTLP endpoint is configured. Exposed on the server Prometheus /metrics surface when the endpoint is enabled. |
runs_on_jobs_queue_fetched | histogram | {message} | Number of job messages fetched from the jobs queue per poll iteration. | - | Exported through OTLP metrics when the stack OTLP endpoint is configured. Exposed on the server Prometheus /metrics surface when the endpoint is enabled. |
runs_on_reconciler_backlog | gauge | {job} | Current number of jobs waiting to be reconciled. | - | Exported through OTLP metrics when the stack OTLP endpoint is configured. Exposed on the server Prometheus /metrics surface when the endpoint is enabled. |
Runner host metrics exported to OTLP by default
Notes:
- Remote OTLP export requires
extras=otel, a configured OTLP endpoint, andJobEnabled=true. - Applies to Linux and Windows.
- Disk metrics are limited to the detected primary/root disk, network metrics to the detected primary network interface, and filesystem metrics are not exported by default.
| Metric | Kind | Unit | Description | Attributes |
|---|---|---|---|---|
system.cpu.load_average.15m | gauge | {thread} | Average CPU Load over 15 minutes. | - |
system.cpu.load_average.1m | gauge | {thread} | Average CPU Load over 1 minute. | - |
system.cpu.load_average.5m | gauge | {thread} | Average CPU Load over 5 minutes. | - |
system.cpu.utilization | gauge | 1 | Difference in system.cpu.time since the last measurement per logical CPU, divided by the elapsed time (value in interval [0,1]). | cpustate |
system.disk.io | sum | By | Disk bytes transferred. | devicedirection |
system.disk.operations | sum | {operations} | Disk operations count. | devicedirection |
system.memory.utilization | gauge | 1 | Percentage of memory bytes in use. | state |
system.network.io | sum | By | The number of bytes transmitted and received. | devicedirection |
Go runtime appendix
| Metric | Kind | Unit | Description | Attributes | Transport |
|---|---|---|---|---|---|
go.config.gogc | observable_up_down_counter | % | Heap size target percentage configured by the user, otherwise 100. | - | Exported through OTLP metrics when the stack OTLP endpoint is configured. Exposed on the server Prometheus /metrics surface when the endpoint is enabled. |
go.goroutine.count | observable_up_down_counter | {goroutine} | Count of live goroutines. | - | Exported through OTLP metrics when the stack OTLP endpoint is configured. Exposed on the server Prometheus /metrics surface when the endpoint is enabled. |
go.memory.allocated | observable_counter | By | Memory allocated to the heap by the application. | - | Exported through OTLP metrics when the stack OTLP endpoint is configured. Exposed on the server Prometheus /metrics surface when the endpoint is enabled. |
go.memory.allocations | observable_counter | {allocation} | Count of allocations to the heap by the application. | - | Exported through OTLP metrics when the stack OTLP endpoint is configured. Exposed on the server Prometheus /metrics surface when the endpoint is enabled. |
go.memory.gc.goal | observable_up_down_counter | By | Heap size target for the end of the GC cycle. | - | Exported through OTLP metrics when the stack OTLP endpoint is configured. Exposed on the server Prometheus /metrics surface when the endpoint is enabled. |
go.memory.limit | observable_up_down_counter | By | Go runtime memory limit configured by the user, if a limit exists. | - | Exported through OTLP metrics when the stack OTLP endpoint is configured. Exposed on the server Prometheus /metrics surface when the endpoint is enabled. |
go.memory.used | observable_up_down_counter | By | Memory used by the Go runtime. | go.memory.type | Exported through OTLP metrics when the stack OTLP endpoint is configured. Exposed on the server Prometheus /metrics surface when the endpoint is enabled. |
go.processor.limit | observable_up_down_counter | {thread} | The number of OS threads that can execute user-level Go code simultaneously. | - | Exported through OTLP metrics when the stack OTLP endpoint is configured. Exposed on the server Prometheus /metrics surface when the endpoint is enabled. |
go.schedule.duration | histogram | s | The time goroutines have spent in the scheduler in a runnable state before actually running. | - | Exported through OTLP metrics when the stack OTLP endpoint is configured. Exposed on the server Prometheus /metrics surface when the endpoint is enabled. |
Generated attribute inventory
RunsOn server metric attributes
| Context | Attribute | Action | Description |
|---|---|---|---|
aws_operation | AWS API operation name. | ||
conclusion | GitHub job conclusion for completed jobs; empty for other states. | ||
github_operation | GitHub API operation name. | ||
installation_id | GitHub App installation identifier. | ||
instance_family | EC2 instance family derived from the resolved runner instance type. | ||
instance_lifecycle | Runner pricing lifecycle such as spot or on-demand. | ||
instance_type | EC2 instance type when a job has been assigned to a runner. | ||
interrupted | Whether the job was interrupted before completion. | ||
limiter | Rate limiter identifier such as github_api or ec2_run. | ||
org | GitHub organization name. | ||
pool_name | Pool name when the job is served from a pool-backed runner. | ||
pool_type | Pool standby type when applicable. | ||
repo_full_name | Repository full name in owner/repo form. | ||
state | Current pool instance state. | ||
status | Job lifecycle status such as queued, scheduled, in_progress, or completed. | ||
workflow_name | GitHub workflow display name. |
RunsOn server resource attributes
| Context | Attribute | Action | Description |
|---|---|---|---|
cloud.region | AWS region when configured. | ||
deployment.environment | Stack environment name when configured. | ||
service.instance.id | Server host identifier when the hostname can be resolved. | ||
service.name | Always runs-on-server. | ||
service.namespace | Stack name when configured. | ||
service.version | RunsOn app version when configured. |
Runner metric attributes exported to OTLP by default
| Context | Attribute | Action | Description |
|---|---|---|---|
cpu | cpu | Logical CPU number starting at 0. | |
cpu | state | Breakdown of CPU usage by type. | |
disk | device | Name of the disk. | |
disk | direction | Direction of flow of bytes/operations (read or write). | |
memory | state | Breakdown of memory usage by type. | |
network | device | Name of the network interface. | |
network | direction | Direction of flow of bytes/operations (receive or transmit). |
Runner resource attributes
| Context | Attribute | Action | Description |
|---|---|---|---|
service.name | insert | Inserted as runs-on-agent when the incoming telemetry does not already define a service name. | |
service.namespace | insert | Inserted as runs-on for runner-generated telemetry when the incoming telemetry does not already define a service namespace. | |
service.instance.id | insert | EC2 instance identifier. | |
deployment.environment | upsert | Configured RunsOn environment name. | |
deployment.environment.name | upsert | Configured RunsOn environment name. | |
stack_name | upsert | RunsOn stack name. | |
region | upsert | AWS region. | |
org | upsert | GitHub organization name. | |
instance_type | upsert | EC2 instance type. | |
instance_lifecycle | upsert | EC2 pricing lifecycle such as spot or on-demand. | |
availability_zone | upsert | EC2 availability zone. | |
ami_id | upsert | AMI identifier used by the runner instance. | |
pool_name | upsert | Pool name when the runner comes from a pool. | |
pool_type | upsert | Pool standby type when the runner comes from a pool. | |
repo_full_name | upsert | Repository full name in owner/repo form. | |
workflow_path | upsert | GitHub workflow file path. | |
job_name | upsert | GitHub job name. |
Go runtime metric attributes
| Context | Attribute | Action | Description |
|---|---|---|---|
go-runtime | go.memory.type | Type of Go runtime memory, currently stack or other. |