Runner platforms - Linux, Windows, GPU
Self-host GitHub Actions runners on AWS across Linux (x64 + arm64), Windows, and GPU — for any GitHub plan. macOS is not yet supported.
RunsOn gives every workflow the full range of AWS EC2 instances as self-hosted GitHub Actions runners, on any GitHub plan (including free plans). This page covers each platform — Linux, Windows, GPU — and how to target it from Flex (per-job labels) and Fleet (Terraform runner fleets).
For per-minute spot and on-demand rates, see the pricing page. To tailor instance shapes or build your own AMIs, see Custom runners & images.
Linux#
RunsOn supports both native x64 and arm64 Linux runners.
Flex#
Pick a predefined runner from the runs-on label — 2cpu-linux-x64 for x64, 2cpu-linux-arm64 for arm64:
jobs: build: runs-on: runs-on=${{ github.run_id }}/runner=2cpu-linux-x64 steps: - run: echo "Hello from x64!"jobs: build: runs-on: runs-on=${{ github.run_id }}/runner=2cpu-linux-arm64 steps: - run: echo "Hello from arm64!"Most users go beyond the predefined names and tailor CPU, memory, family, and volume with job labels or custom runners.
Fleet#
Define the runner shape in Terraform, publish it as a fleet, then target the fleet from workflow YAML:
runners = { linux-small = { family = ["c8i.large"] image = "ubuntu24-full-x64" }}
fleets = { linux-small = { runner = "linux-small" }}jobs: build: runs-on: runs-on/fleet=linux-small/env=productionDefault images#
Opt into a specific image with the image label. When you set image, make sure your family uses instance types matching the image architecture (e.g. family=c7g+m7g for arm64).
| Image | Architecture | Description |
|---|---|---|
ubuntu22-full-x64 | x64 | Compatible with the official Ubuntu 22.04 GitHub runner image. |
ubuntu24-full-x64 | x64 | Compatible with the official Ubuntu 24.04 GitHub runner image. |
ubuntu22-full-arm64 | arm64 | Compatible with the official Ubuntu 22.04 GitHub runner image. |
ubuntu24-full-arm64 | arm64 | Compatible with the official Ubuntu 24.04 GitHub runner image. |
Examples#
Disable spot pricing for critical jobs:
jobs: build: runs-on: runs-on=${{ github.run_id }}/runner=2cpu-linux-x64/spot=falseOnly allow 4-CPU instances from compute-optimized families:
jobs: build: runs-on: runs-on=${{ github.run_id }}/runner=4cpu-linux-x64/family=c7Fully custom definition — launched in a private subnet with a static egress IP:
jobs: build: runs-on: runs-on=${{ github.run_id }}/ram=8/family=m7+c7+r7/image=ubuntu24-full-x64/spot=false/ssh=false/private=trueNeed help choosing? Use the instance finder ↗ to match AWS instances to your CPU, RAM, and architecture requirements.
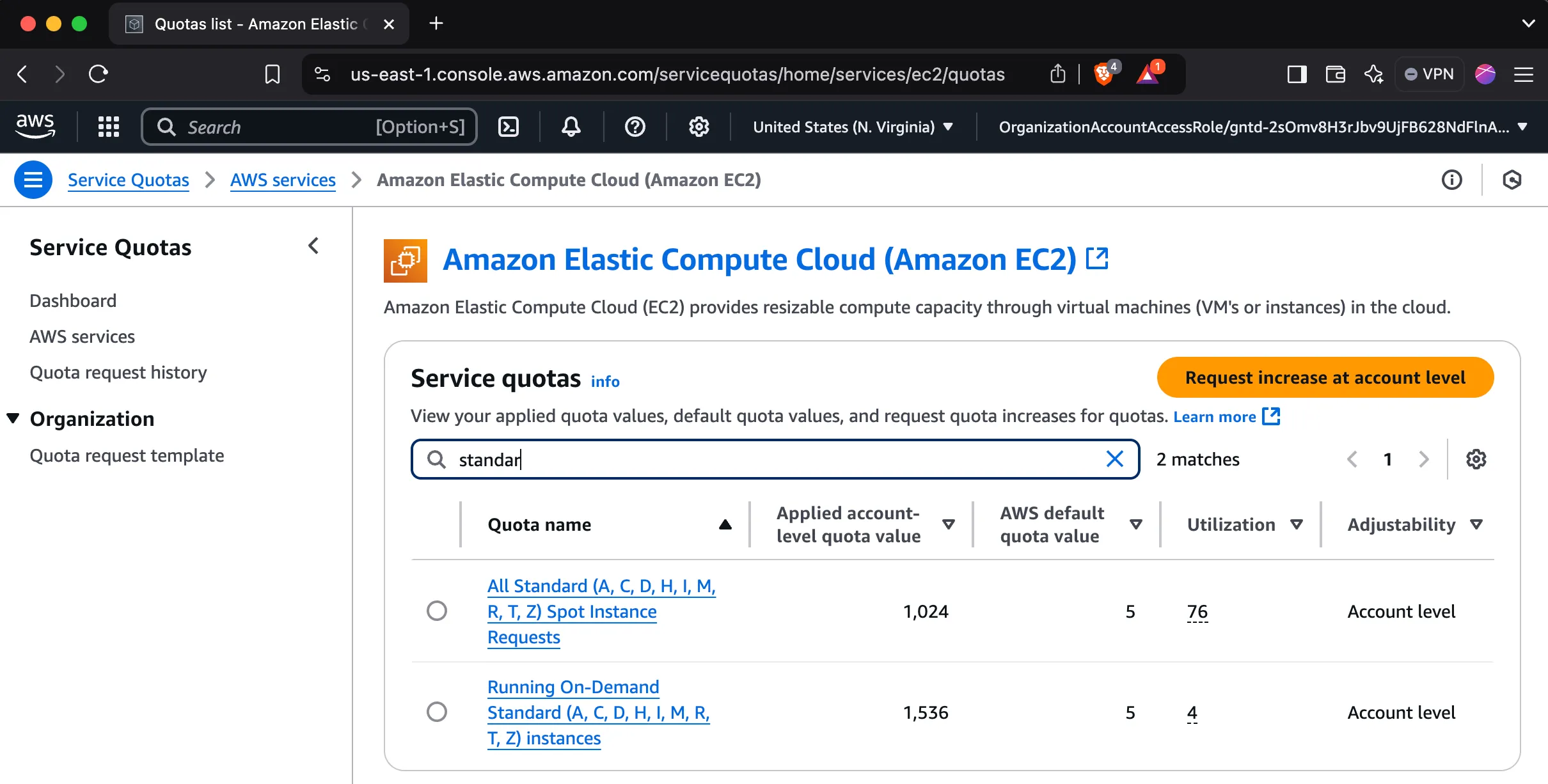
Quotas#
New AWS accounts have low default quotas for standard instances, so you may need an increase to launch many jobs.
How to request an increase
- Search for “Quotas” in the AWS console.
- Click “Request quota increase”.
- Select “EC2” as the service.
- Select the standard instance type.
- Fill in the form and submit (you request vCPUs, not instance count).
- Repeat for both spot and on-demand quotas.
Windows#
Windows self-hosted runners are available since v2.4.0, and are ~10x cheaper than the official GitHub Actions Windows runners (for example on the m7i family). See pricing for current rates.
Flex#
Select a Windows image and x64 EC2 family in the job label:
jobs: build: runs-on: runs-on=${{ github.run_id }}/image=windows25-full-x64/family=m7iFleet#
Publish a Windows runner fleet in Terraform and target the fleet label:
runners = { windows = { family = ["m7i.large"] image = "windows25-full-x64" }}
fleets = { windows = { runner = "windows" }}jobs: build: runs-on: runs-on/fleet=windows/env=productionDefault images#
| Image | Architecture | Description |
|---|---|---|
windows22-full-x64 | x64 | Windows Server 2022, mostly compatible with the official Windows 2022 GitHub runner image. |
windows25-full-x64 | x64 | Windows Server 2025, mostly compatible with the official Windows 2025 GitHub runner image. |
windows22-base-x64 | x64 | Base Windows 2022 image — boots faster, no preinstalled software. |
windows25-base-x64 | x64 | Base Windows 2025 image — boots faster, no preinstalled software. |
Example#
name: Windows
on: workflow_dispatch:
jobs: default: runs-on: runs-on=${{ github.run_id }}/image=windows22-full-x64/family=m7i steps: - name: Checkout uses: actions/checkout@v6 - name: Check current dir and env variables run: | dir . echo $env:USERNAME echo $env:RUNS_ON_RUNNER_NAME - name: Logs run: | Get-Content -Path "C:\runs-on\output.log" - name: Users run: | Get-LocalUser | Format-Table -AutoSize Name,Enabled,PasswordLastSetInspecting agent logs#
On Windows runners, the RunsOn agent output is stored in C:\runs-on\output.log. Those logs are also shipped to the CloudWatch log group for EC2 instances.
Limitations#
- Windows runners are slow to boot (~1min for base images, ~2-3min for full images). Warm pools can reduce this to 20-30 seconds.
- Hyper-V-dependent workloads require explicitly opting into
nested-virton supported x64 families such asm8i. - Some legacy or easily-installable software has been removed to ensure faster boot times and lower disk usage.
GPU#
RunsOn gives you the full range of GPU EC2 instances — NVIDIA (T4, A10G, L4, L40S, M60, V100, A100, H100, H200) and AMD (Radeon Pro V520) — for much cheaper than the official GitHub Actions GPU runners (typically ~10x cheaper on spot; see pricing). Available on all GitHub plans, including free.
Flex#
Select a GPU-capable EC2 family and a GPU image in the job label:
jobs: gpu: runs-on: runs-on=${{ github.run_id }}/family=g5.xlarge/image=ubuntu24-gpu-x64Fleet#
Publish a GPU runner fleet in Terraform and target the fleet label:
runners = { gpu = { family = ["g5.xlarge"] image = "ubuntu24-gpu-x64" }}
fleets = { gpu = { runner = "gpu" }}jobs: gpu: runs-on: runs-on/fleet=gpu/env=productionGPU images#
Since v2.6.5, RunsOn provides official gpu images pre-configured with the latest NVIDIA driver, CUDA toolkit, and container toolkit, on top of the standard full image software. Recommended for most use cases.
| Image | Architecture | Description |
|---|---|---|
ubuntu22-gpu-x64 | x64 | Ubuntu 22.04 + NVIDIA driver, CUDA toolkit, container toolkit. |
ubuntu24-gpu-x64 | x64 | Ubuntu 24.04 + NVIDIA driver, CUDA toolkit, container toolkit. |
ubuntu24-gpu-arm64 | arm64 | For NVIDIA GPU runners on Graviton instances such as g5g + NVIDIA driver, CUDA toolkit, container toolkit. |
Workflow example#
jobs: default: runs-on: "runs-on=${{ github.run_id }}/family=g4dn.xlarge/image=ubuntu24-gpu-x64" steps: - name: Display NVIDIA SMI details run: | nvidia-smi nvidia-smi -L nvidia-smi -q -d Memory - name: Ensure Docker is available with GPU support run: docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi - name: Execute your machine learning script run: echo "Running ML script..."For ARM64 GPU workloads, use ubuntu24-gpu-arm64 with a compatible family such as g5g:
jobs: arm64-gpu: runs-on: "runs-on=${{ github.run_id }}/family=g5g.xlarge/image=ubuntu24-gpu-arm64" steps: - name: Display NVIDIA SMI details run: | nvidia-smi uname -mDeep Learning AMIs#
Combined with custom images, you can use AWS’s official Deep Learning AMIs ↗ (DLAMI). Define a custom image referencing the latest DLAMI and a custom runner referencing that image and your GPU family — see Custom runners & images for the full setup. Note that DLAMI-based runners take longer to start because the base image is very large; a streamlined custom image built with Packer boots faster.
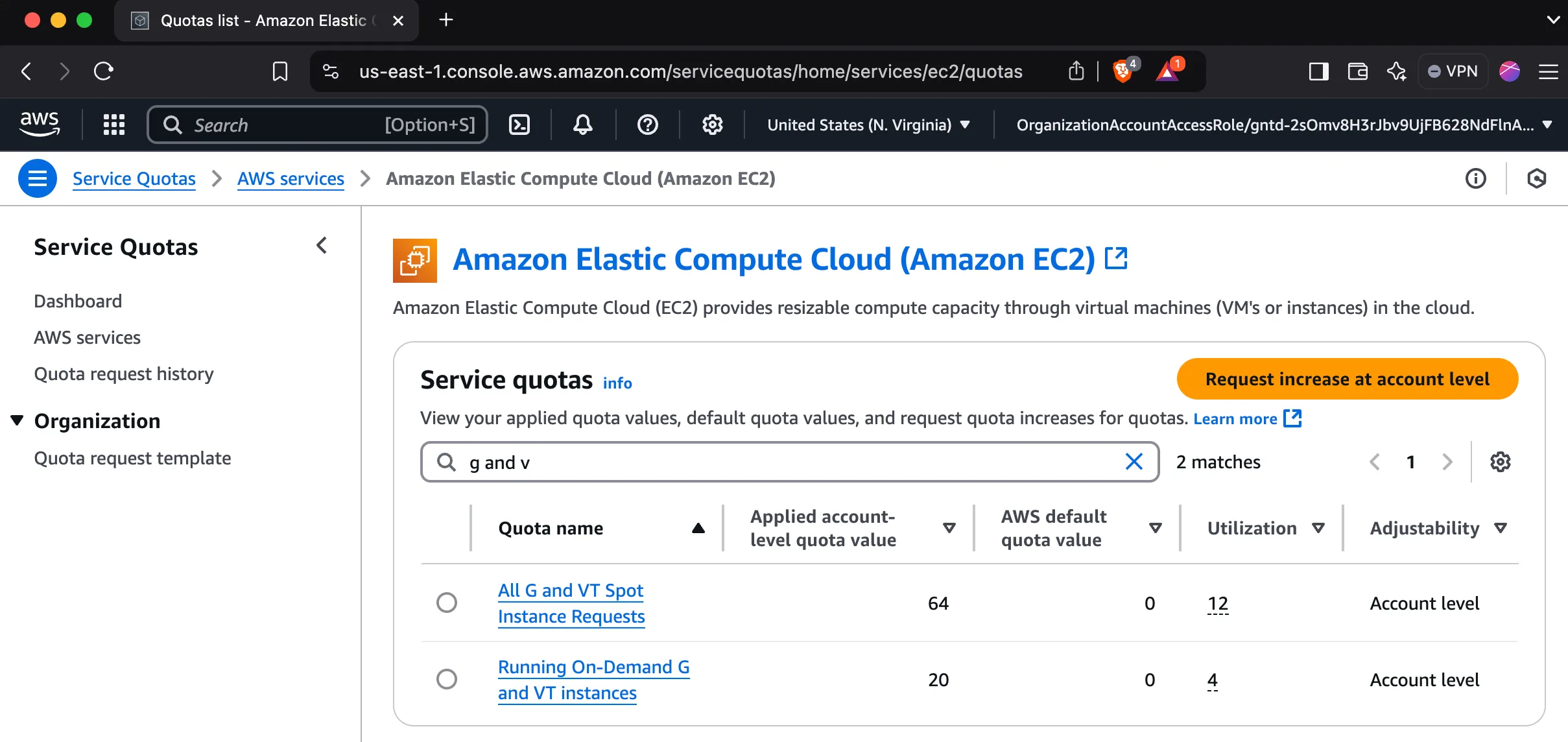
Quotas#
New AWS accounts have GPU instance quotas set to zero by default, so you will likely need to request an increase.
How to request an increase
- Search for “Quotas” in the AWS console.
- Click “Request quota increase”.
- Select “EC2” as the service.
- Select “G” as the instance type.
- Fill in the form and submit.
- Repeat for both spot and on-demand quotas.
macOS#
macOS runners are not yet supported by RunsOn, due to licensing constraints enforced by Apple ↗. Neither Flex nor Fleet can launch macOS capacity today.
Billing for EC2 Mac instances is per second with a 24-hour minimum allocation period to comply with the Apple macOS Software License Agreement.
That 24-hour minimum is the blocker: RunsOn’s shared-nothing model keeps every client in control of their own hosts, so it cannot pool short-lived CI jobs across clients to amortize a 24-hour reservation the way centralized providers can. As soon as this licensing limitation is lifted, RunsOn will support macOS runners. For now, keep macOS jobs on GitHub-hosted or a dedicated macOS runner provider.