Warm pools
Learn how to use runner warm pools to get <10s queuing time for your GitHub Actions workflows on self-hosted runners.
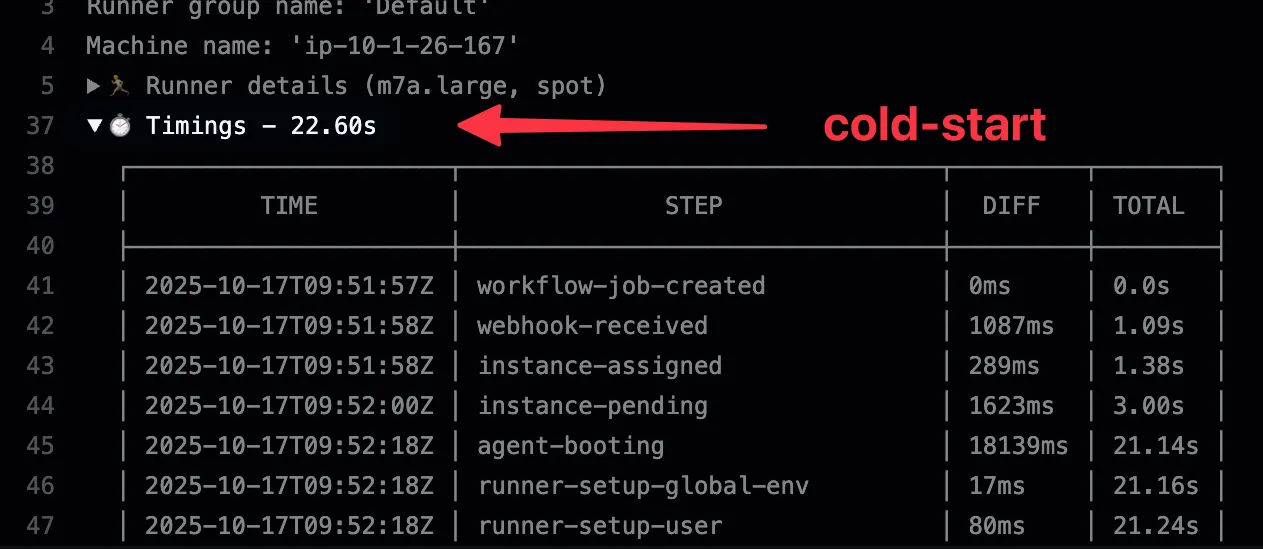
Runner pools allow you to pre-provision runners that are ready to pick up jobs immediately, dramatically reducing queue times from ~25 seconds (cold-start) to under 6 seconds (hot instances). This is ideal for improving developer experience, reducing wait times for smaller jobs, and achieving predictable performance.
Available since v2.9.0.
Expected Queue Times
For Linux runners (m7a-type instances):
| Instance Type | Queue Time | Use Case |
|---|---|---|
| Cold-start | < 25s | Default behavior, most cost-efficient |
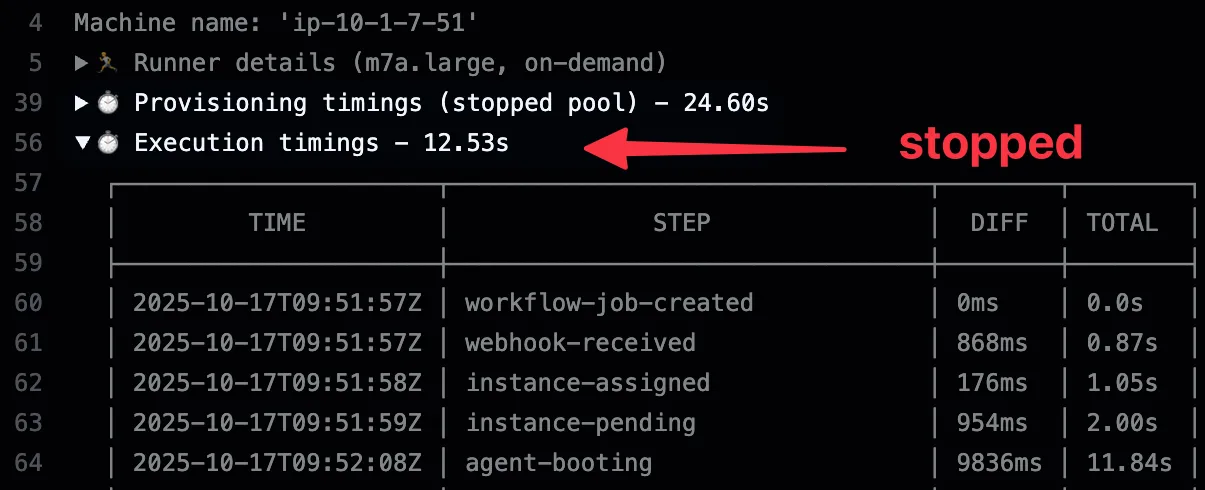
| Stopped | < 15s | Pre-warmed EBS, balanced cost/performance |
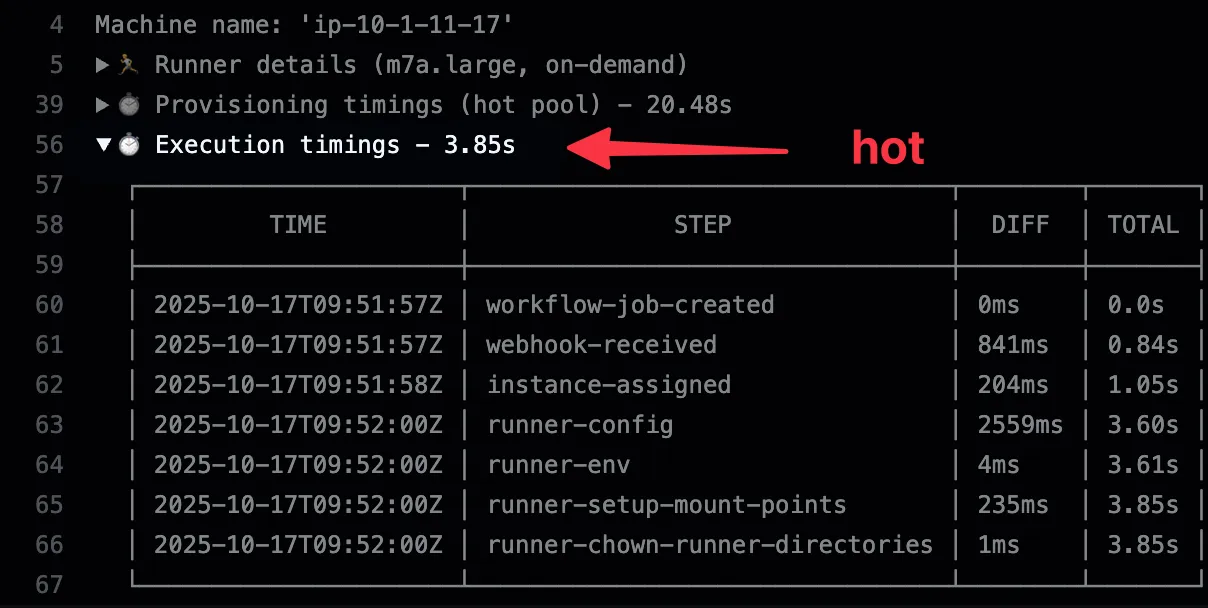
| Hot | < 6s | Always running, fastest response time |
For Windows runners:
| Instance Type | Queue Time |
|---|---|
| Cold-start | < 3min |
| Stopped | < 40s |
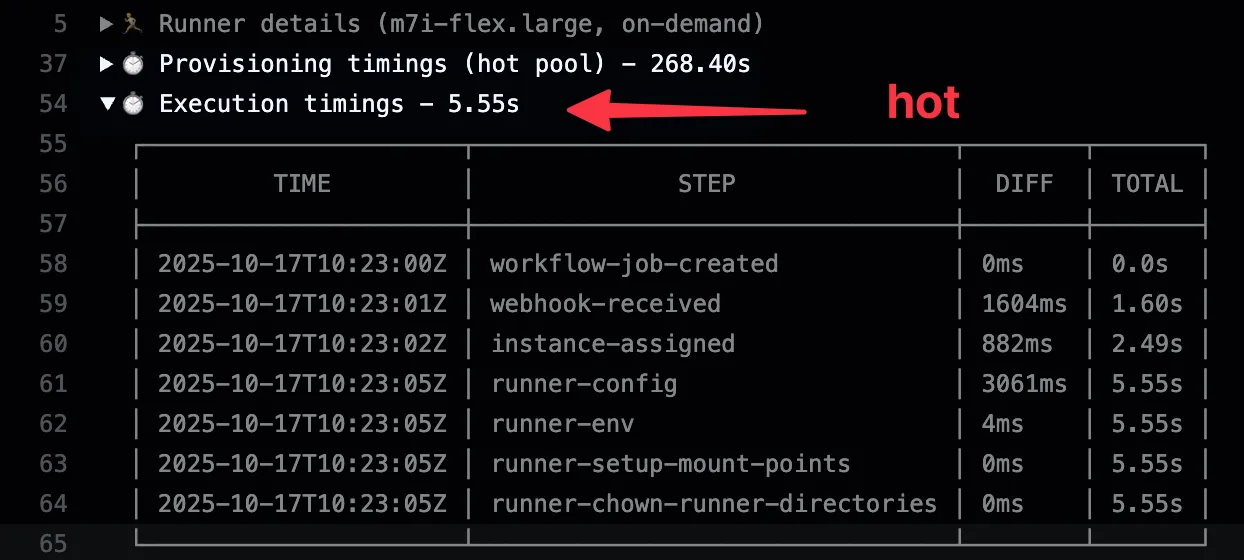
| Hot | < 6s |
Pool Types
Hot instances stay running and ready to accept jobs immediately. They provide the fastest response times but incur EC2 compute costs. Hot instances are automatically terminated after 16h of idle time to ensure they stay fresh and up-to-date.
Stopped instances are pre-provisioned, warmed up, and then stopped to minimize costs. When a job arrives, they start quickly (EBS volume is already warmed, dependencies installed). You only pay for EBS storage while stopped, making them a good balance between cost and performance.
Configuration
Pools are always configured in the .github/runs-on.yml file in your organization’s .github-private repository. This single file serves as the source of truth for all pool configurations.
Basic Example
# .github-private/.github/runs-on.yml
runners:
small-x64:
image: ubuntu24-full-x64
ram: 1
family: [t3]
volume: gp3:30gb:125mbps:3000iops
pools:
small-x64:
env: production
runner: small-x64
timezone: "Europe/Paris"
schedule:
- name: default
stopped: 2
hot: 1This configuration:
- Defines a custom runner named
small-x64with 1GB RAM - Creates a pool named
small-x64that maintains 2 stopped instances and 1 hot instance - Uses Paris timezone for schedule calculations
Advanced Example with Scheduling
pools:
small-x64:
env: production
runner: small-x64
timezone: "America/New_York"
schedule:
- name: business-hours
match:
day: ["monday", "tuesday", "wednesday", "thursday", "friday"]
time: ["08:00", "18:00"]
stopped: 5
hot: 2
- name: nights
match:
day: ["monday", "tuesday", "wednesday", "thursday", "friday"]
time: ["18:00", "08:00"]
stopped: 2
hot: 0
- name: weekends
match:
day: ["saturday", "sunday"]
stopped: 1
hot: 0
- name: default
stopped: 2
hot: 1This creates different pool capacities based on your usage patterns:
- Business hours (weekdays 8am-6pm): 5 stopped + 2 hot instances
- Nights (weekdays 6pm-8am): 2 stopped instances, no hot instances
- Weekends: 1 stopped instance only
- Default: Fallback for any unmatched time periods
Configuration Options
| Field | Description |
|---|---|
env | Stack environment this pool belongs to (e.g., production, dev) |
runner | Reference to a runner definition in the runners section |
timezone | IANA timezone for schedule calculations (e.g., America/New_York, Europe/Paris) |
schedule | List of schedule rules with capacity targets |
schedule[].name | Human-readable name for this schedule |
schedule[].match.day | Array of days (monday-sunday) when this schedule applies |
schedule[].match.time | Time range [start, end] in 24-hour format |
schedule[].stopped | Number of stopped instances to maintain |
schedule[].hot | Number of hot instances to maintain |
Using Pools in Workflows
To use a pool in your workflow, add the pool=POOL_NAME label to your runs-on definition:
jobs:
test:
runs-on: runs-on/pool=small-x64
steps:
- uses: actions/checkout@v6
- run: npm testFor more deterministic runner-to-job assignment:
jobs:
test:
runs-on: runs-on=${{ github.run_id }}/pool=small-x64
steps:
- uses: actions/checkout@v6
- run: npm testWhen using pool labels, all other RunsOn labels (like cpu, ram, family) are ignored. Only the runner specification defined in the pool configuration is used.
Automatic Overflow
If your pool is exhausted (all instances are in use), RunsOn automatically creates a cold-start instance to handle the job. This ensures jobs never fail due to lack of capacity:
Job arrives → Check pool capacity → Instance available? → Pick from pool (fast)
→ No capacity? → Cold-start instance (fallback)Dependabot Integration
Pools enable using RunsOn for Dependabot jobs. If you define a pool named dependabot, it will automatically be used for any Dependabot jobs:
# .github-private/.github/runs-on.yml
# You must define the runner that the pool will use
runners:
small-x64:
image: ubuntu24-full-x64
ram: 2
family: [t3]
volume: gp3:30gb:125mbps:3000iops
pools:
dependabot:
env: production
# must reference a runner defined in the `runners` section above
runner: small-x64
schedule:
- name: default
stopped: 2
hot: 0When RunsOn sees a job with the dependabot label, it automatically expands it internally to the equivalent of runs-on/pool=dependabot.
Note that you need to enable Dependabot to run on self-hosted runners, in your GitHub repository settings, otherwise they will still be launched on GitHub official runners.
Cost Considerations
Storage Costs for Stopped Instances
Stopped instances still incur EBS storage costs. To minimize expenses:
runners:
efficient-runner:
volume: gp3:30gb:125mbps:3000iops # Free tier eligibleHot Instance Costs
Hot instances incur both EC2 compute and storage costs while running. They are automatically recycled after 16 hours (or on pool capacity changes due to schedule, etc.) of idle time to:
- Keep costs under control
- Ensure instances stay updated with latest AMI
- Prevent long-running instances from accumulating issues
Cost Comparison
Assuming an m7a.medium instance (on-demand price: $0.07/hour) with 30GB gp3 storage ($0.08/GB-month), available 24/7, 7 days a week
| Type | EC2 Cost | Storage Cost | Total/Month (1 instance) |
|---|---|---|---|
| Hot | ~$50.40/month (24/7) | ~$2.40/month | ~$52.80/month |
| Stopped | $0 | ~$2.40/month (24/7) | ~$2.40/month |
| Cold-start | $0 | $0 | $0 (pay per use) |
Note that with schedules, you can make those hot or stopped instances run only for half a day and not on weekend, so your real costs would be lower.
Availability
Pools are available for both Linux and Windows runners. They are especially useful in the following cases:
- you have short jobs that are queued frequently, and you want them to be executed as fast as possible.
- you are using Windows runners, and don’t want to wait multiple minutes for them to start up.
- you are preinstalling a lot of dependencies in your runners with the
preinstallfeature, and you want that process to be done during the warm-up phase so that you get much better pick-up times for your jobs.
Limitations
- On-demand instances only: Spot instance support for hot instances will be added once pools are considered stable
- SSH access: Only stack default admins are added to pool instances (if SSH is enabled). SSM access is still working as expected.
FAQ
How do I know if my pool is working?
Check the EC2 console for instances with the runs-on-pool tag matching your pool name. You should see instances in various states (warming-up, ready, detached).
You also get monitoring widgets in the embedded CloudWatch dashboard, as well as OpenTelemetry metrics (if enabled).
What happens if I delete a pool from config?
The pool manager will automatically terminate all instances in that pool during the next convergence cycle.
Can I use spot instances for hot pools?
Not yet. Hot pool instances currently use on-demand pricing. Spot support will be added once pools are stable.
What if my job needs custom labels (cpu, ram, etc.)?
Pool jobs ignore all labels except pool, env, and region. To customize runner specs, define them in the pool’s runner configuration in .github-private/.github/runs-on.yml.
How do I update my runner configuration?
Simply update the runner definition in .github-private/.github/runs-on.yml. The pool manager will automatically detect the change (via spec hash) and roll out new instances within a few convergence cycles (~1-2 minutes).
Can I have multiple pools with different specs?
Yes! Define multiple entries in the pools section, each referencing different runners:
runners:
small: { ram: 1, ... }
large: { ram: 16, ... }
pools:
pool-small: { runner: small, ... }
pool-large: { runner: large, ... }How It Works
Pool Manager
A pool manager process runs a convergence loop every 30 seconds that:
- Fetches configuration from
.github-private/.github/runs-on.yml - Matches schedule to determine current target capacity (hot/stopped counts)
- Rebalances instances to match target capacity
- Updates states of instances through their lifecycle
Instance Lifecycle
Pool instances move through these states (tracked via runs-on-pool-standby-status EC2 tag):
| State | Description |
|---|---|
warming-up | Instance is being created, EBS warming, running preinstall scripts |
ready | Instance is available to be picked up for jobs |
ready-to-stop | Stopped-type instance that has completed warmup, ready to be stopped |
detached | Instance picked up for a job, no longer managed by pool |
error | Instance encountered an error during setup |
Rebalance Algorithm
On each 30-second cycle, the pool manager:
- Categorizes instances by state (hot, stopped, outdated, error, etc.)
- Terminates error instances that failed setup
- Terminates dangling instances that should have started jobs but didn’t
- Terminates outdated instances with old spec hash (runner config or AMI changed)
- Happens immediately to free AWS quota before creating new instances
- Stops ready-to-stop instances (stopped-type that finished warmup)
- Creates missing instances to reach target capacity (batched creation)
- Terminates excess instances beyond target capacity
Spec Hash and Rollouts
Each pool instance is tagged with a spec hash that includes:
- Runner configuration (CPU, RAM, disk, image)
- AMI ID
- Pool configuration
When you update runner configuration or a new AMI is published, the pool manager automatically:
- Detects outdated instances (spec hash mismatch)
- Terminates them to free AWS quota
- Creates new instances with the updated specification
This ensures pools always run the latest configuration and AMI versions.
Batch Operations
To handle large pools efficiently:
- Termination: Batched up to 50 instances per EC2 API call
- Creation: Uses EC2 Fleet API to create multiple instances atomically
- Starting stopped instances: Batched up to 50 instances per API call
Safety Mechanisms
Instances are protected from termination when:
- Job has started (
runs-on-workflow-job-startedtag is set) - Instance is detached from pool (status =
detached) - Instance is currently executing a workflow job
The rebalance algorithm explicitly filters out these instances before any termination operations.